This section describes the major steps involved in designing and implementing the underlying infrastructure of the TABIS data warehouse. These steps are grouped into four categories, and described in the following sections: Section 4.1 hardware and software design considerations, Section 4.2 data acquisition, Section 4.3 data integration, and Section 4.4 database optimization. Not all of the techniques describes in these sections are research, but the information is included in this dissertation to provide the reader with a more complete understanding.
This section describes how the hardware and software used to implement the Textile and Apparel Business Information System (TABIS) were chosen. The term "hardware" describes the physical equipment, such as the computers, disk drives, and the network. "Software" refers to the computer programs, such as programming languages and the database management tools.
Unix workstations, connected via Ethernet, were chosen as the main hardware development platform for this research.
Specifically, the hardware chosen as the development platform was a DECstation 5000/25 Unix workstation (running Ultrix) with 24Mb of RAM, 200Mb internal hard drive, 3.5" floppy diskette drive, an additional 1Gb external hard drive which can store as much data as approximately 1,000 3.5" floppy diskettes (Figure 4.1), and an Apple LaserWriter IIg Postscript printer with 8Mb RAM. All components were connected to the NCSU Ethernet network and can be shared via the Internet. The main factors considered in the hardware selection were capacity, speed, supportability, accessibility, and security.
The TABIS system requires the capacity to store and manipulate large files, and accommodate multiple users. For example, the Census population projection data set is a typical "large" file in the TABIS system - the "raw" ASCII Census data file is 800 characters wide, 15,600 lines long, and occupies about 12Mb of disk space. Many computers (eg, PCs) and software packages (eg, spreadsheets) can not handle files of this size.
Another requirement of TABIS is the capacity to serve multiple users. Multiple users can simultaneously access TABIS using any of the more than 1,300 DEC, Sun, or HP workstations on the Ethernet at NCSU via the AFS file server -- this type of access allows multiple users and allows distributed processing.
Another factor in the hardware selection criteria was speed. The speed of most PC-based systems is limited by the hardware itself. For example, the cd-rom drives used in most PC-based data analysis systems are inherently slower than hard drives. Also, the small amount of RAM in most PC-based systems (8Mb-12Mb) makes queries to large data sets slow or impossible. Unix workstations, on the other hand, generally have at least 16Mb-24Mb of RAM, with at least twice that amount of "virtual RAM" (swap space) on the local hard drive. Also, the data sets are stored on SCSI hard drives, which allow much quicker access than the cd-rom drives.
Supportability was also a major consideration. Since maintaining networked computers and file servers is not an end-user task, equipment was chosen that already had a campus-wide support infrastructure in place at NCSU.
Users need convenient 24-hour access to TABIS. Many of the 1,300 workstations in various computer rooms, labs, and graduate and faculty offices across the NCSU campus allow 24-hour access. Users can also dial-in 24 hours a day, or login remotely from another computer connected to the Internet.
Unlike most PCs, Unix workstations provide several levels of security. Each valid user of the workstations at NCSU is assigned an account which is protected with a password, and provides the users with a certain amount of disk space where they have write-permission. Also, Andrew's File System (AFS) allows Access Control Lists (ACLs) which allow users to access the TABIS data, but not modify it. AFS, as opposed to other file systems such as NFS, allows read and/or write permission to be granted on a per-user basis -- this capability allows proprietary datasets to be shared with fellow research team members as needed, while protecting them from the general public.
The SAS System was chosen to provide data storage, query, and analysis capabilities, and the C programming language was used to write the TABIS interface. SAS and C proved to be a very versatile and flexible software selection.
SAS provides Relational Database (RDB) capabilities (data tables and SQL queries) in addition to data analysis and graphical capabilities. SAS is also portable across almost all computer architectures, and the extensive SAS programming language allows analyses to be automated. SAS is also available free-of-charge on all the NCSU Unix workstations through a 10-year $1,000,000 grant from SAS Institute. [SAS_SQL] [Kent]
A relational database (RDB) system was chosen because it is particularly well-suited for storing tables of data, and integrating the tables with SQL queries. Other database systems such as object-oriented, network, and hierarchical were considered, but could not provide the convenience and functionality of the relational system for the table-oriented needs of TABIS. [Codd] [Date]
SAS was chosen over relational database management systems (RDBMSs), such as Oracle and Sybase, for several reasons. First, licensing, support, and training for a new software is cost-prohibitive, whereas all these are already in place at NCSU for the SAS System. Also, most other RDBMSs lacked the data analysis, plotting, and mapping capabilities that are an integral part of the SAS System, and the RDBMSs include a lot of overhead for live transaction processing which is not needed for the TABIS data. [Kern]
Deciding which programming language to use to write the user interface was perhaps the most difficult decision. The various built-in SAS interface languages, such as the SAS Screen Control Language (SAS/SCL) and SAS Application Frame (SAS/AF), were considered since they provide a graphical user interface (GUI) with much of the desired functionality already built-in. Several GUI interfaces which have gained recent popularity, such as the World Wide Web browsers, were also considered. The reasons these "easy-to-program" user-friendly GUIs were rejected in favor of the C programming language are described below.
One reason the
C programming language
was chosen is
portability
-- C
compilers
exist for all computer platforms, from PCs to mainframes, and C
programmers and documentation are abundant. Another reason is functionality -- for example,
the C system command can be used to submit jobs directly to SAS, or
start a Unix animation program such as xanim or mpeg_play. The C language also
provides a high degree of flexibility -- an
ASCII
menu written in C can be accessed
through even the most basic form of login, such as an ASCII
dial-in
session,
dumb-terminal,
or even a
hard-copy terminal.
Also, users can run the C-based menu, and generate the desired query and analysis code, without actually submitting the code to the SAS database -- therefore, they do not need a SAS license on their computer to try out the menu and see what is available in TABIS, or to generate sample code. Also, by writing the interface in C, instead of using one of SAS's GUI languages, the TABIS menus can be more easily ported to a different database and analysis software if the need arises in the future.
The data acquisition was primarily conducted by Carl Priestland, the Chief Economist of the American Apparel Manufacturers Association (AAMA). Carl used his expert knowledge of data sources, along with his personal contacts, to obtain a unique collection of textile- and apparel-related data from over 20 sources (see Section 2.4.2 for the complete list).
The data were obtained in many different formats, and on many different physical media types. The formats include: ASCII, compressed ASCII, dBase, Quattro Pro, Excel spreadsheets, Lotus 123 spreadsheets, WordPerfect documents, and printed tables. The physical media types include: reel-to-reel tape, cartridge tape, 3.5" floppy diskette, 5.25" floppy diskette, CD-ROM, and paper hard-copy (Figure 4.2).
After the acquisition phase, the data were transformed into an integrated structure and format so they could be merged into the data warehouse. [Inmon]
In the first step of the integration process, a sub-directory was created under
the tabis/data/ directory on the 1Gb disk for each of the data sources
(Figure 4.3).
For example, the County Business Patterns
(CBP)
data files were placed in the
tabis/data/cbp/ directory.
Each data file was then converted to standard
ASCII
(Figure 4.4)
to allow all the data to be easily handled in the same manner. These ASCII files
also provide a simple means of spot-checking the data values by viewing the ASCII
data with Unix tools like grep and the xedit editor.
This conversion process was very time-consuming for some of the formats. For example, converting the DOS dBase files to ASCII required finding a PC with dBase software, then reading the data into dBase, writing the data from dBase to several DOS ASCII files (since the entire data set would not fit on a single DOS 3.5" 1.44Mb floppy diskette), loading the ASCII files into the Unix workstation, converting the files from DOS ASCII to Unix ASCII, and then joining the multiple ASCII file pieces into a single ASCII file.
SAS programs were then written to convert the ASCII files into SAS tables (aka SAS data sets)
(Figure 4.5).
The SAS tables are stored in the tabis/datasets/ directory where
all TABIS queries have direct access to them without the overhead of reading
the ASCII files and creating a SAS dataset at the time of the query.
One difficulty encountered was that the SAS data sets for DEC workstations
need to be in a different SAS format (.ssd02) from the SAS data sets for Sun and HP workstations (.ssd01).
Therefore 2 different copies of all the data sets were maintained, and
symbolic links using the AFS @sys variable, such as datasets->.datasets.@sys
were created so that no matter which hardware architecture the user is
executing TABIS on, (eg, DEC, Sun, or HP), the correct data sets for their hardware
architecture appear in the tabis/datasets/ directory.
Another difficulty encountered was that some data sets changed format, variable names, and column locations from year to year, requiring customized programs to be written to read in the data each year. The most difficult data set was the Bureau of Labor Statistics Consumer Expenditures (BLS/CE) -- slight modifications to their file formats and variable names over an 8 year period required 629 lines of SAS code to read the data into a coherent SAS data set. The Bureau of Labor Statistics Employment and Earnings (BLS/EE) data set, by comparison, only required 60 lines of SAS code to read in over 50 years of data.
A special Unix utility, called
Make,
was utilized to automatically run the SAS programs to
update the SAS data sets (ie, targets) when the ASCII data files or the SAS programs
used to read in the ASCII data files (ie, dependency list) change.
Make's configuration files, called Makefiles, allow the TABIS administrator to re-build the data sets, when needed,
by simply typing tabismake (tabismake is the front-end script that sets the needed Unix
environment variables, and then runs the regular Unix make command).
The Makefiles check the dependency list for each "target", and run the list of
commands to re-make the target if any file in the dependency list has been changed
more recently than the target.
There is also a "master" Makefile located in the tabis/data/ directory
(this is the directory that holds all the ASCII data files) that
can be used to run all the other Makefiles, and re-make the entire SAS
tabis/datasets/ library (this is the directory that holds all the sas data sets).
The Makefiles are particularly useful in maintaining
copies of the SAS data sets for multiple hardware platforms.
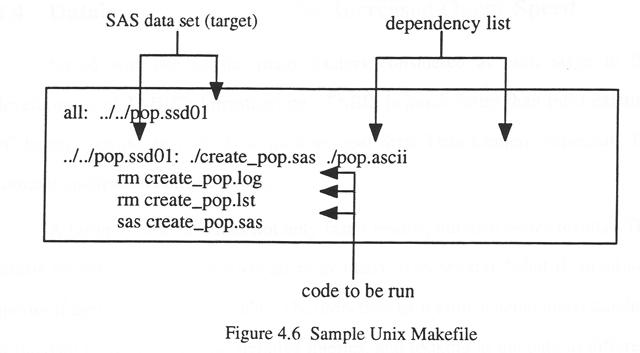
Figure 4.6
shows a simplified "Makefile" that could be used to re-make the
Census Population Projection data set. If either the create_pop.sas program,
or the pop.ascii file has changed more recently than the pop.ssd01 SAS data set,
the three lines of code will be automatically run to generate a new pop.ssd01 data set.
Although Makefiles are routinely used to re-compile C code, this is perhaps the first use of Makefiles to maintain a data warehouse of SAS data sets. The technique proved to be very convenient in maintaining the TABIS data warehouse for multiple architectures.
Speed was one of the major factors considered at each stage in the development of TABIS's infrastructure. TABIS is much faster than most existing PC-based systems, such as those used in most State Data Centers, especially for complex queries on large data sets.
A faster system provides not only faster results, but also better results. The results are better because the users are more likely to try several "what-if" or ad-hoc queries if the response time is quick. The users then gain a much better understanding of the data by making several iterative queries, and looking at the data in different ways.
The hardware selection played a major role in the speed of TABIS queries (see Section 4.1.1), but the database programming techniques which were learned and applied are perhaps even more important, particularly from a research perspective. Several of those techniques are described in Sections 4.4.1 - 4.4.5.
Perhaps the most significant factor in improving the speed of TABIS's queries was converting the ASCII files into SAS data sets (see Section 4.3). The alternative would be to read the ASCII files into SAS data sets at the time the user issues the query, which can require over 15 minutes for some of the larger ASCII files -- such a long wait would not meet the needs of the users. With the ASCII files already converted to SAS data sets, complicated queries to even the largest data sets take less than one minute.
Most speed enhancements have a cost, and the cost for this enhancement is
disk space.
Now, in addition to the
ASCII
copy of the data in the tabis/data/
directory, a second copy (the SAS data set) must be stored in the tabis/datasets/ directory.
Also, since the Suns and DECstations each have a different format for SAS data sets,
an additional copy of the data set must be made. This makes a total of three copies of
each data -- one ASCII file, one DECstation SAS data set (.ssd02), and one Sun/HP SAS data set (.ssd01).
The benefit of an approximate ten-fold reduction in query time is well worth the cost
of the additional disk space.
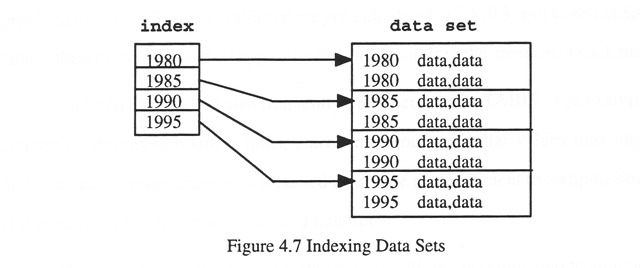
Another technique used to increase the speed of queries to large data sets was indexing. An index for a data set is analogous to an index at the end of a book. For example if a data set is sorted by year, and then indexed by year (see Figure 4.7), queries can "jump" directly to the desired year's data, based on the information in the index. Speed increases of two-to three-fold were achieved in some of TABIS's data sets by indexing.
Although indexing can increase the speed of queries to large data sets, it can actually hurt performance on "small" data sets. For small data sets, the overhead involved in consulting an index can be greater than the time required to consult the data set without an index. Many experts were consulted, and experimentation was done to determine which of TABIS's data sets would benefit from indexing.
Many of the raw data values must be converted to a more useful form before being presented to the user. Unit conversions, for example, are also frequently pre-calculated in TABIS. Converting dozens into single units, converting thousand dollar values into single dollar values, or other frequently accessed values are more efficient to compute once, and store the pre-calculated values in a data set.
Also, some of the custom geographical maps require additional calculations for special effects - these calculations are performed ahead of time, where possible. One pre-calculation which saves a great deal of interactive time was performed on the "US Maps by County" data set -- a query was required to create state outlines for these county maps, since the state outlines were not included in the county maps provided by SAS. The state outlines were pre-calculated in TABIS, and stored as SAS data sets, thereby saving the user approximately 45 seconds in the creation of each map.
Where practical, these conversions and pre-calculations are done ahead of time, and stored as SAS data sets, thereby eliminating the time needed to perform such calculations each time the users issue their queries. The cost of this time-saving technique, as with the previous two techniques, is the amount of disk space needed to store the pre-calculated values.
Accessing a small data set is quicker than accessing a large data set, therefore efforts were made to reduce the size of the TABIS data sets. One method used was to specify the number of bytes used to store values in SAS data sets, rather than using the default value, in some cases.
For example, each numerical SAS variable is stored using 8 bytes of disk space by default. Many of the TABIS variables, such as year, contain values that can be stored using less than 8 bytes. Where possible, these smaller values were stored using less than 8 bytes in the TABIS data sets, thereby reducing the amount of disk space needed, and improving the query speed.
Other methods for reducing the data set size, such as splitting and normalizing the tables, increase the complexity of the queries greatly, therefore making it more difficult for users to write their own queries and extensions. These techniques were used only where the space savings would outweigh the added complexity.
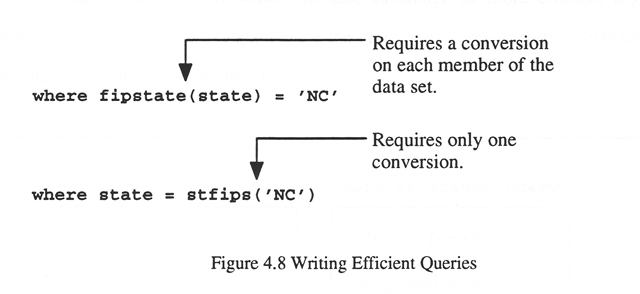
In spite of all the previous techniques used to improve performance, many queries still had poor response time. In these cases, the queries themselves were rewritten in a more efficient manner to improve their speed. Figure 4.8 shows an example of a coding improvement that saves thousands of calculations in some queries -- the response time was reduced from an unacceptable 5 minutes to a quick 15 seconds in some cases
Similarly, better programming techniques were found to test for the existence of a pattern in a string. Initially, the "index" function was used, and the mathematical result was tested. Later, it was found that SAS's built-in "?" ("contains") function provides a much more efficient test for the existence of a pattern in a string (see Figure 4.9).

Also, queries were re-written to take advantage of more efficient SQL techniques to join tables. A comparison of the "traditional" versus a more efficient technique are shown in Figure 4.10.
